天才后浪养成系列 - 1. 网络数据爬虫技术简介
这是天才后浪养成系列第一期,我们以天才后浪网为例,简要介绍网络数据爬虫技术以及相关的Python代码实现。
前言
前几天刷微信朋友圈无意间看到一篇文章:赞!中国神童们!数天完成普通硕博十年研究,未来靠你们了!。文中的天才少年们在STEM(科学,技术,工程,数学)且不仅限于STEM的各个领域出类拔萃、各领风骚。出于对天才少年们的敬仰之情,作者去文中提到的天才后浪网站浏览了一下。结果不看不知道,一看吓一跳,没想到后浪已然这般的汹涌澎湃了,我们这帮搬砖的老浪还未在生活的大浪里站稳脚跟就已被拍在了沙滩上。毛主席说骄傲使人落后,虚心使人进步,所以我辈决定本着一颗谦卑的心,深入研究天才后浪们的学术成就和成功经验,以兹将后浪的治学精神发扬光大。
内容预告
天才后浪系列会以天才后浪网为例,介绍网络数据爬虫技术,数据统计分析,数据挖掘,机器学习和深度学习,自然语言处理等内容。本期主要围绕数据爬虫技术,介绍相关的基本概念和具体的Python实现。
基本概念和设置
网络数据爬虫是指用计算机程序从互联网上自动爬取数据,是继开放数据集和API之后的第三种网络数据收集手段。通过浏览天才后浪网,我们发现天才后浪的项目获奖数据十分丰富,正如下面的截图显示,其中科创板块共有326个页面,每个页面有12个项目展示,包括项目成员信息、所在地区、学科分类、项目摘要、图表结果和获奖情况等。这对于我们搬砖老浪来说,是宝贵的学习资料,也是激励我们粪发向上的动力。
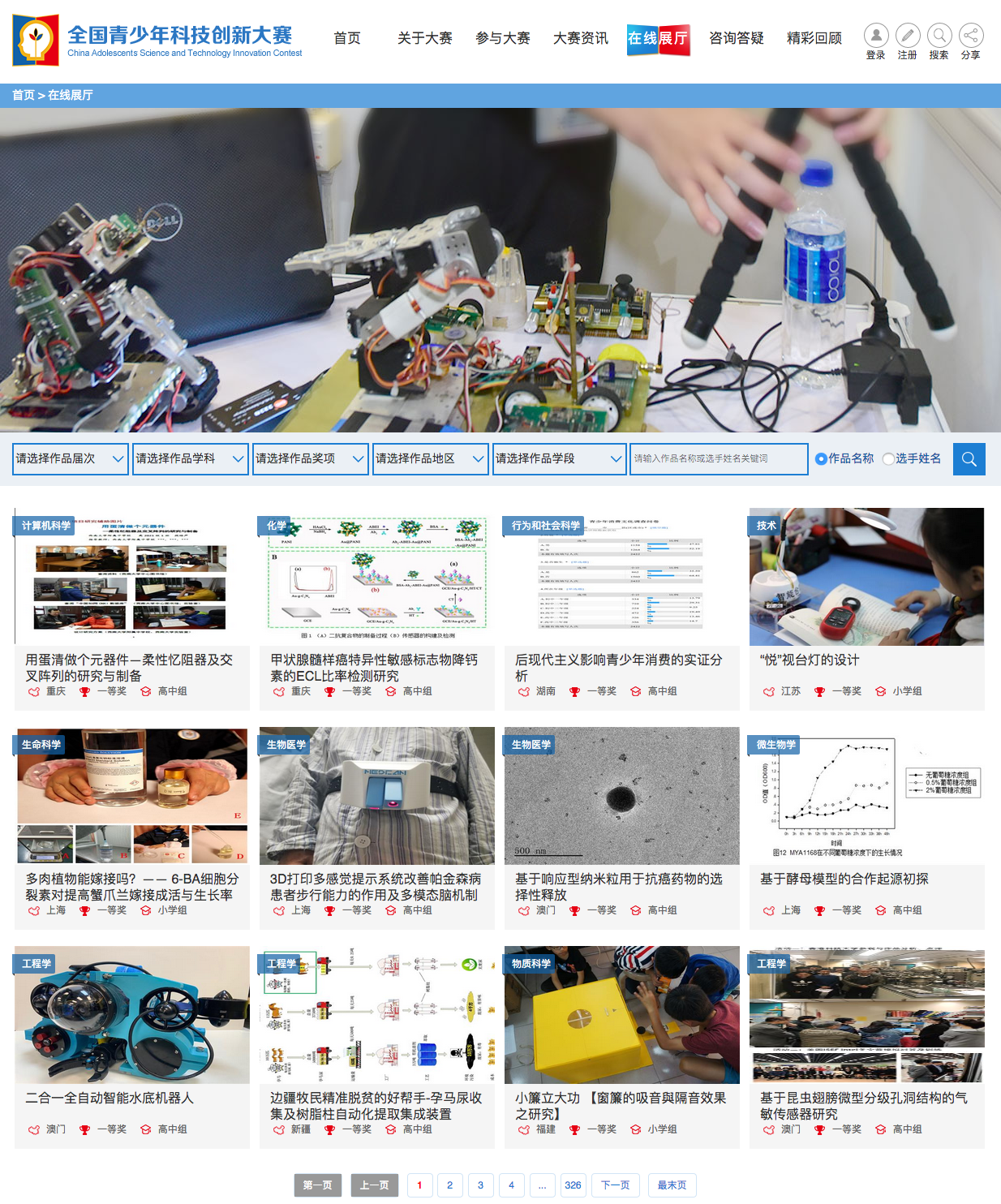
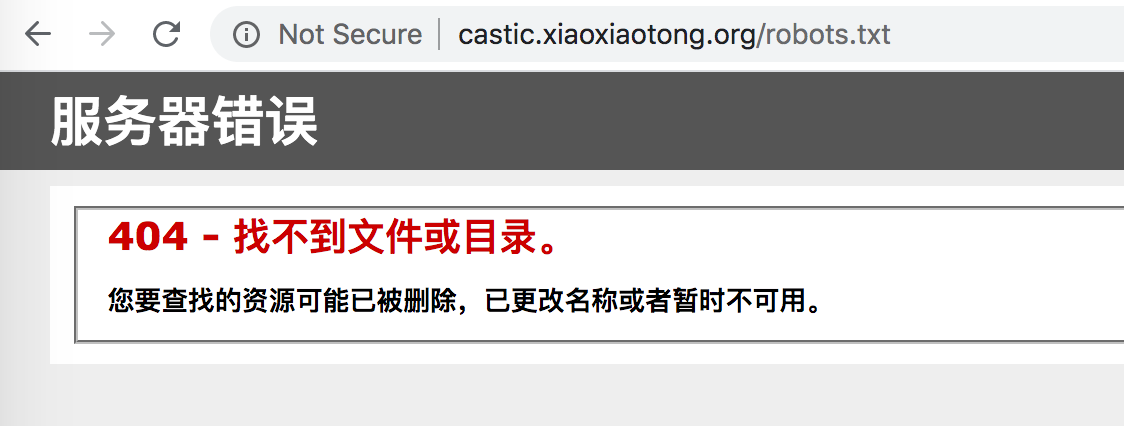
天才后浪网是目前唯一可以获得这些信息的网站,同时也没有API可供下载。由于这些数据是公开信息,同时当我们在URL添加robots.txt时发现网站并没有限制数据爬取的约定(如下图所示),因此我们满怀感激地开始了向天才后浪们致敬的学习计划,在这里也由衷地感谢天才后浪网愿意分享天才后浪们成功经验的开源精神。
考虑到通用性和易用性,我们这里使用Python设计网络数据爬取程序。Python是一个面向对象的通用脚本语言,近年来由于物联网、人工智能和数据科学的兴起,Python得到了广泛的关注和应用。目前最普遍使用的开源Python编译器是Anaconda系列。读者可以在Anaconda官方网站上免费下载安装对应操作系统的Python编译器。天才后浪养成系列中用的是Python 3.7版本。
在安装好Python后,我们还需要一些常用的库(library),它们可以通过pip安装:
pip install argparse
pip install multiprocessing
pip install numpy
pip install pandas
pip install requests
pip install beautifulsoup4
pip install selenium
其中selenium需要安装对应的浏览器驱动,例如Firefox对应的驱动为geckodriver(https://github.com/mozilla/geckodriver/releases)。Chrome浏览器的驱动可以从这里下载:https://chromedriver.chromium.org/downloads。解压驱动文件后,将其移至/usr/bin或者/usr/local/bin,因为在执行时,程序会从这两个地址中寻找对应的浏览器驱动文件。
网络数据爬虫技术
网络数据大体可以分为静态数据和动态数据两种,其中静态数据是指数据本身已在HTML文档中,直接保存HTML就能把数据保存下来,对应常用的Python库是requests或urlib2;动态数据是指数据不在HTML里,需要进一步的操作(一般是执行一段Javascript程序)后才能看到。对于动态数据,直接利用requests.get()无法得到目标信息,这时我们就需要编写程序驱动浏览器,模拟手动操作来获取相应数据,常用的库是selenium。需要注意的是由于selenium需要打开浏览器模拟手动操作,所以速度相较于requests会慢的多。所以在编写程序之前,我们需要对目标网站的结构和数据格式有所了解,从而使用相应的工具获取数据。
我们可以利用浏览器提供的工具初步分析目标网站,例如在Firefox浏览器中, 依次点击“Tools” → "Web Developer" → "Inspector",就会在右侧栏中看到网页对象对应的HTML代码:

通过利用Inspector工具对天才后浪网的分析,我们发现主要有两类信息需要爬取:项目获奖列表信息和项目详细信息,对应的URL分别为:http://castic.xiaoxiaotong.org/Query/StudentQuery.aspx 和 http://castic.xiaoxiaotong.org/Query/SubjectDetail.aspx?SubjectID=***。可以看出天才后浪项目的详细信息是需要通过在URL中输入SubjectID来获得的,而每个项目页面的URL则是可以在项目获奖列表页面中找到。天才后浪项目列表页面的翻页则是通过执行一句Javascript程序实现的,如下图所示:

基于上述观察,我们制定了天才后浪项目数据爬取的三步计划:1. 利用selenium模拟翻页,获取天才后浪项目列表及获奖信息;2. 根据第一步的SubjectID列表,利用requests获取各个天才后浪项目的详细信息;3. 最后合并前两步获得的数据。前两步的Python实现如下:
1. 获取天才后浪项目列表及获奖信息
import selenium
from selenium import webdriver
url = "http://castic.xiaoxiaotong.org/Query/StudentQuery.aspx"
page = 1
# launch the browser driver
driver = webdriver.Chrome()
# get the project list page
driver.get(url)
# go to corresponding page
script = "javascript:__doPostBack('AspNetPager1','"+format(page)+"')"
driver.execute_script(script)
# save the project list page to html file
open('page'+format(page)+'.html', 'w').write(driver.page_source)
2. 获取各个天才后浪项目的详细信息
import requests
from bs4 import BeautifulSoup
# parse the page html
soup = BeautifulSoup(open('page1.html', 'r'), 'html.parser')
# get the href for each project on that page
for item in soup.find_all('a', class_="item", href=re.compile("ID=")):
# get project detail pages
r = requests.get(item['href'])
if r.status_code == 200:
# save the project detail pages to html files
open(item['href'].split('=')[-1])+'.html', 'wb').write(r.content)
最后我们将历年来天才后浪们辉煌的学术成就整理到一个Excel表格中(其中隐去了项目成员信息),欢迎读者下载和学习:https://github.com/yhyoscar/AutoData/blob/master/genius/data/merge_projects.xlsx
相关法规及约定须知
网络数据爬取技术是一把双刃剑,原则上只有公开数据才可以爬取,比如这里的天才后浪网的项目及获奖信息;私有数据,比如个人信息,一般来说是不能以商业盈利为目的来爬取的。此外,一般网站上会在robots.txt里约定哪些数据是可以爬取的公开数据、哪些是私有数据。